Using clickthrough data to build robust image concept detectors

Clickthrough data are the collected from the search logs of image search engines. They consist of the user-submitted text queries and the images the users clicked in respond to a query. Figure 1 shows an example of clickthrough data from the Bing image search engine (taken from Clicture dataset) for queries that contain the term “windmill”.
Clicktrough data are fairly cheap to collect and require no effort from the users. This implicit user feedback can be used for image annotation and training set generation; however, due to its nature can lead to training sample annotations that suffer from great label noise (i.e., high probabilities for erroneous labels).
Initially [1,2,3] we studied the use of clickthrough data for building image concept detectors using 100,000 images with query logs provided by the image search engine of the Belga news agency. A methodology based on language models was proposed in order to retrieve a sufficient number of relevant images for each concept. Experiments showed that the contribution of query log based training data is positive despite their inherent noise; in particular, the combination of manual and automatically generated training data outperforms the use of manual data alone. These results showed that it is possible to use clickthrough data to perform large-scale image annotation with little manual annotation effort or, depending on performance, using only the automatically generated training data. However, it was also evident that when the label noise increases, detector performance suffers.
Subsequent research work with image clickthrough data focused on quantifying and using label uncertainty in order to increase the robustness of concept detectors. More specifically we introduced
- Methods using weighted SVM algorithms that achieve high performance and impressive noise resilience.
- High-performance online learning “analogues” of the weighted SVM algorithms for learning and continuous model update from streams of individual clicks.
2. A pipeline for training noise-resilient SVM-based concept detectors
Clickthrough data consist of triplets in the form \( (Q_i, I_j, N_{ij}) \) indicating that the image \( I_j \) was clicked \( N_{ij} \) times by the users of the search engine in respond to the textual query \( Q_i \). We consider that clickthrough data are aggregated; i.e., individual clicks or user sessions cannot be distinguished.

In [4] we showed that robust image concept detectors can be trained using the procedure illustrated in Figure 2. It consists of the following steps:
-
A textual representation \( T_j \) for the \( I_j \) image is created by the concatenation of \( Q_i \). The repetitions \( N_{ij} \) are taken into account, thus, the query \( Q_i \) is included \( N_{ij} \) times in the constructed textual representation.
-
Let \( c \) the concept name for which we are interested in building a concept detector. We use \( c \) as a text query against the textual documents \( T_j \) of the images to assign relevance scores with the use of Information Retrieval (IR) relevance methods. Thus, the procedure of scoring the images becomes a simple IR problem between a text query and text documents. In [4], three IR methods were evaluated: Vector Space Models (VSM), Language Models (LM) and BM25.
-
Let \( score_m(c,T_j) \) be the relevance score of the image \( I_j \) with respect to a concept \( c \) using relevance method \( m \). Images with positive \( score_m(c,T_j) \) are taken as the positive samples of the training set. Images with zero score construct the pool from which we sample the negative images of the training set.
-
The scores of the positive samples are used to generate sample weights for weighted SVM algorithms. The standard SVM and three SVM variants were evaluated: fuzzy SVM (FSVM), power SVM (PSVM), and bilateral-weighted fuzzy SVM (BFSVM). The specific weight generation procedure followed for each algorithm is described in [4].
A similar approach was followed in [5] where Language Models were used in combination with stemming and/or keyword expansion to generate scores of different noise levels.
3. Key results
3.1 Comparison of the examined IR relevance methods
Although the three examined relevance methods are excellent for typical IR problems, we need to evaluate their effectiveness in our task. Intuitively, a relevance method that is able to assign higher scores for the true positive images will lead to better performance for the weighted SVM methods.
In order to evaluate the IR methods, we selected 40 concepts and constructed training sets using the proposed procedure on the Clicture-lite dataset. Then, we manually annotated the candidate positive images to calculate the true positive rate.
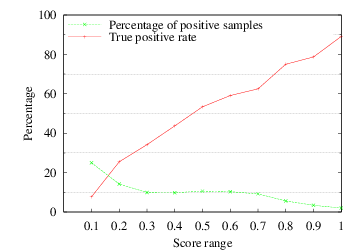

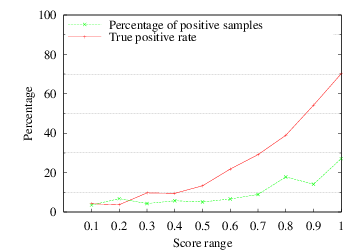
Figures 3, 4 and 5 show the true positive rate and the percentage of candidate positive images over the normalised relevance scores for each method.
Finding #1: VSM is the best among the examined relevance methods. It assigns high relevance scores to true positive images and implicitly “filters” a great amount of the non-relevant images by assigning them with low relevance scores. An additional interesting property of VSM is that the normalised scores follow fairly closely the probability of label correctness for the candidate positive images.
3.2 Evaluation of the combinations of weighted SVM algorithms and relevance methods
For each relevance method and 40 selected concepts standard SVM and weighted SVM concept detectors are trained. The concept detectors are applied on a test set of \( 500.000 \) images of the Clicture-lite dataset and the top 100 images retrieved from each concept detector are manually annotated to calculate the Normalised Discounted Cumulative Gain (\(nDCG\)) at various depths. Table 1 shows the average \(nDCG\) for the 40 concepts at level 100.
| Vector Space Models | BM 25 | Language Models | |||||||
| SVM | FSVM | PSVM | BFSVM | FSVM | PSVM | BFSVM | FSVM | PSVM | BFSVM |
| 0.1178 | 0.2481 | 0.1604 | 0.2598 | 0.1627 | 0.1485 | 0.1547 | 0.1862 | 0.1518 | 0.1912 |
The results provide us with the following important findings.
Finding #2: All weighted SVM concept detectors and with any relevance method perform better than the standard SVM that does not use weights.
Finding #3: Each weighted SVM variant performs better with weights generated using the VSM relevance scores. This confirms our observation for the properties of the VSM scoring method discussed above.
Finding #4: The best performance is achieved using BFSVM (improvement 120.5% over standard SVM) followed closely by FSVM (improvement 110.6% over standard SVM).
3.3 Robustness to different levels of label noise for weighted SVM algorithms
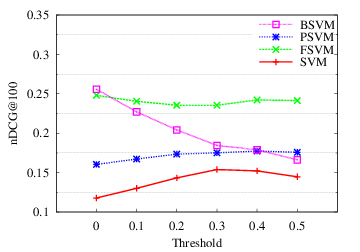
Finally, we examine the performance of the concept detectors on varying levels of label noise. For this purpose, we apply thresholds on the normalised VSM scores; higher thresholds lead to more noise-free training sets. Figure 6 shows the average \(nDCG@100\) over 40 concepts for varying threshold values.
Finding #5: The most resilient weighted SVM variant for the task is FSVM that maintains high performance for arbitrary levels of label noise.
Finding #6: Cleaning the training set—by applying thresholds to exclude the most noisy images—improves the performance of standard SVM. Nevertheless, after certain thresholding the performance deteriorates since valuable positive images are lost. Most important in no case the standard SVM concept detectors were able to achieve perfomance comparable to weighted SVM solutions that were trained on the complete (and very noisy) training sets.
Relevant Publications
- Theodora Tsikrika, Christos Diou, Arjen P. de Vries and Anastasios Delopoulos. "Reliability and effectiveness of clickthrough data for automatic image annotation". Multimedia Tools and Applications, 55, (1), pp. 27-52, 2010 Aug
- Ioannis Sarafis, Christos Diou and Anastasios Delopoulos. "Building effective SVM concept detectors from clickthrough data for large-scale image retrieval". International Journal of Multimedia Information Retrieval, 4, (2), pp. 129-142, 2015 Jun
- Ioannis Sarafis, Christos Diou and Anastasios Delopoulos. "Online training of concept detectors for image retrieval using streaming clickthrough data". Engineering Applications of Artificial Intelligence, 51, pp. 150-162, 2016 Jan