1. Why streaming clickthrough data?

In our previous work, we presented an overview methods for building noise resilient concept detectors based on batch-trained weighted SVM algorithms. These methods can be only applied after a considerable amount of the clickthrough data has been collected. Alternatively, one can regard clickthrough data as stream of clicks that is constantly incoming to the search engine (as in Figure 1).
Treating clickthrough data as streams to train and update concept detectors with online machine learning methods may lead to significant advantages:
- Allows training of concept detectors for new/trending concepts as soon as they are identified.
- The concept detectors can be up-to-date regarding novel visual aspects of existing terms or concepts, “guided” by the users’ feedback.
- Search engines can evolve and adapt to the users’ needs.
- Online machine learning methods are efficient for consuming large amounts of streaming data since they do not require all training samples to be loaded simultaneously into the memory.
2. Online learning as an approximation of fuzzy SVM
Part 1 concluded that fuzzy SVM is the most effective and noise resilient weighted SVM algorithm, producing concept detectors of high performance for varying levels of label noise. Our aim is to transfer this effectiveness and robustness into the online learning setting.
Let us consider a training set that contains \( N \) discrete training samples: \[ T = \{ ( \mathbf{x}_i^1, y_i), \dots, (\mathbf{x}_i^{n_i}, y_i)| i = 1, \dots, N \} ~~~ (1) \] Essentially, this training set can be collected by monitoring the clickthrough stream; \( \mathbf{x}_i \) are the visual feature vectors of the images and \( n_i \) are the number of clicks for each image.
It can be shown that training a standard SVM on the training set of (1) is mathematically equivalent to training a fuzzy SVM an a reduced dataset where each sample \( \mathbf{x}_i \) appears only once but with fuzzy SVM sample weight analogous to the number of repetitions. Thus, using an online-trained SVM algorithm (in our experiments we used LASVM) we can infer a inferred batch-trained sample-weighted analogue. For more details on the connection between batch and online training using clickthrough data see [1].
3. Sketch of the proposed approach
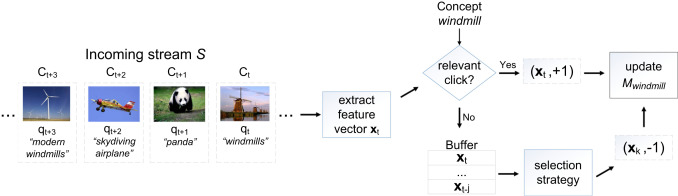
Figure 2 displays the sketch of the proposed online learning approach from streaming clickthrough data. All the relevant clicks with respect to the concept name are used as positive samples for online concept detector updating. On the other hand, the non-relevant clicks forms a, typically large, pool of candidate negative samples.
Through this setting we are able to:
- Treat each individual click only once and as soon as it becomes available.
- Update the concept detectors using solely the incoming stream of clicks.
-
The importance of each click is implicitly maintained in the online concept detector models using appropriate learning algorithms, such as LASVM. In LASVM an image with more clicks with respect to a concept is more likely to become a support vector. Also, important images (i.e., with more relevant clicks) may result in multiple copies of support vectors. This provides a mechanism for implicit importance weighting in the feature space.
4. Selecting good negative samples
Candidate negative samples (originating from the non-relevant clicks) form the vast amount of clicks. Selecting good negative samples is important for the performance and the convergence of the online concept detectors. Three selection criteria for online LASVM-based concept detectors were evaluated in [1]:
- Random: Negative samples are randomly sampled from the non-relevant clicks of the stream.
- Gradient: The non-relevant click which gives the highest gradient in the SVM objective function is selected.
- Active: The non-relevant click that is closest to the separating hyperplane is selected.
5. Key results
5.1 Evaluation of the online-trained concept detectors
For 30 selected concepts online LASVM-based models are trained using the three selection criteria on a development set of \( 500.000 \) images of the Clicture-lite dataset. The clickthrough streams are emulated using the aggregated clickthrough data of the datasets. The models are tested on \( 500.000 \) test images from the same dataset and the top 100 images retrieved from each concept detector are manually annotated to calculate the Normalised Discounted Cumulative Gain (\(nDCG\)) at various depths. For comparison purposes, standard SVM and fuzzy SVM models are trained and evaluated using the same development and test set splits. Table 1 shows the average \(nDCG\) at level 100 for the 30 selected concepts. For fuzzy SVM concept detectors we use weights for the positive images that are analogous to the number of relevant clicks.
| Batch-trained | Online-trained | |||||||||
| Gradient – selection pool size | Active – selection pool size | |||||||||
| SVM | fuzzy SVM | Random | 2 | 4 | 8 | 10 | 2 | 4 | 8 | 10 |
| 0.215 | 0.384 | 0.258 | 0.301 | 0.362 | 0.38 | 0.383 | 0.297 | 0.358 | 0.378 | 0.384 |
Finding #1: The online concept detectors—trained one click at a time—outperform the standard SVM concept detectors which are supplied with the total training set beforehand. Most importantly, the online concept detectors demonstrate effectiveness that is equivalent to the batch-trained fuzzy SVM concept detectors.
Finding #2: Both gradient and active selection criteria increase the effectiveness of the online concept detectors compared to random selection.
5.2 Evaluation of the convergence speed of the selection criteria

The results of Table 1 display the performance of the concept detectors at the end of the click stream. Now, we focus at the beginning of the click streams to see the effect of the selection criteria in the convergence speed of the online concept detectors. Figure 3 shows the average \(nDCG@100\) over the 30 concept at the beginning of the streams when up to 100 relevant clicks (i.e., positive samples) have been fed to the online concept detectors.
Finding #3:Gradient selection criterion displays the greatest convergence speed and yields high performance concept detectors even after a small number of relevant clicks.
5.3 Evaluation of the noise resilience of the online concept detectors
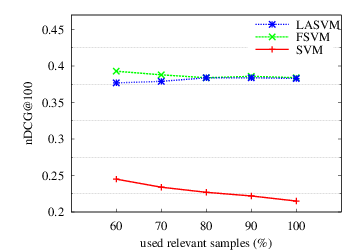
Finally, we evaluate the robustness of the online concept detectors to label noise. The different noise levels are created artificially by removing noisy images from the development set: the images are ranked according to the number of relevant clicks and a progressively larger portion of noisy images—the images with the fewer relevant clicks—is removed from the development set. Then, the remaining of the development set is used to create training sets for the SVM/ Fuzzy SVM and online LASVM concept detectors with fewer, and thus less noisy, positive samples.
Figure 4 shows the average \(nDCG@100\) over the 30 concepts. Larger number of used samples results to higher label noise levels during concept detector training
Finding #4: The online concept detectors maintain the high robustness to noise of the batch-trained weighted SVM counterparts. On the other hand, the standard SVM concept detectors suffer from great performance deterioration when noisy samples are introduced in the training sets. This finding confirms the key role of sample weighting both in batch (where weights are directly calculated) and online approaches (where an implicit importance weighting in the feature space is achieved using the click repetitions).
6. Relevant Publications
- Ioannis Sarafis, Christos Diou and Anastasios Delopoulos. "Online training of concept detectors for image retrieval using streaming clickthrough data". Engineering Applications of Artificial Intelligence, 51, pp. 150-162, 2016 Jan