The SPLENDID chewing detection challenge dataset was created in the context of the EU funded SPLENDID project. This dataset contains approximately 60 hours of recordings from a prototype chewing detection system. The sensor signals include photoplethysmography (PPG) and processed audio from the ear-worn chewing sensor, and signals from a belt-mounted 3D accelerometer. The recording sessions include 14 participants and were conducted in the context of the EU funded SPLENDID project, at Wageningen University, The Netherlands, during the summer of 2015. The purpose of the dataset is to help develop effective algorithms for chewing detection based PPG, audio and accelerometer signals. Evaluation scripts for MATLAB are also available on GitHub.
Download links
The dataset can be downloaded from here. Make sure you download the second version of the dataset (v2).
The evaluation MATLAB scripts can be downloaded from here.
If you plan to use this dataset or other resources you’ll find in this page, please cite our papers
[1] V. Papapanagiotou, C. Diou, L. Zhou, J. van den Boer, M. Mars and A. Delopoulos, “The SPLENDID chewing detection challenge,” 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, South Korea, 2017, pp. 817-820.
doi: 10.1109/EMBC.2017.8036949
URL: http://ieeexplore.ieee.org/document/8036949/
[2] V. Papapanagiotou, C. Diou, L. Zhou, J. van den Boer, M. Mars and A. Delopoulos, “A Novel Chewing Detection System Based on PPG, Audio, and Accelerometry,” in IEEE Journal of Biomedical and Health Informatics, vol. 21, no. 3, pp. 607-618, May 2017.
doi: 10.1109/JBHI.2016.2625271
URL: http://ieeexplore.ieee.org/document/7736096/
Recording equipment
Prototype chewing sensor combines an audio microphone and a PPG sensor, housed together in a common ear hood.
Audio microphone: FG-23329-D65 model from Knowles. Placed inside the outer ear canal where body-generated sounds, including chewing sounds, are naturally amplified due to ear physiology, while external environmental sounds are somewhat dampened.
PPG sensor: BPW34FS photo-diode and SFH4247 LED from Osram. Photo-diode placed inside the ear concha facing down and slightly backward, and LED placed behind the ear, facing towards the photo-diode. Variations in light, and thus in blood flow, contain information regarding chewing activity.
Prototype data-logger, integrated 3D accelerometer LIS3DH by STMicroelectronics.
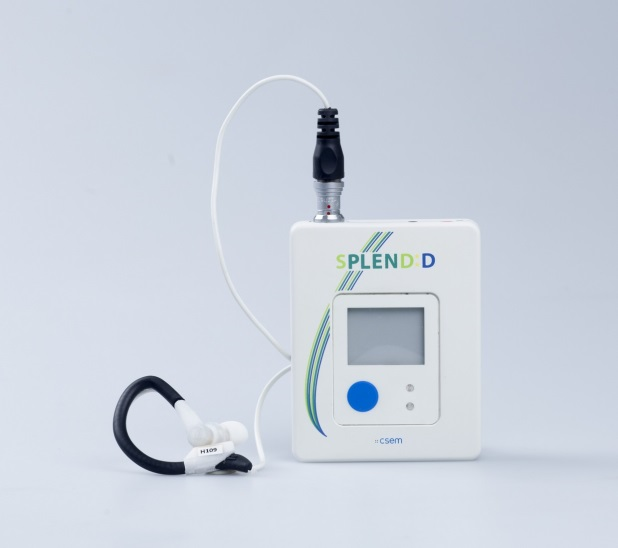

Data collection
The recording trials were conducted during June of 2015 at Wageningen University. In total, 22 individuals (19 female and 3 male) with mean age of 22.9 years and mean body-mass-index (BMI) of 28 kg/m^2 participated; 19 of them participated during two different days, two weeks apart, and the remaining 3 participated during a single day. Each recording day lasted approximately 5 hours, split into 2 or 3 sessions.
Each day, three participants were using the equipment simultaneously. Upon arrival, the participants were introduced to the system and recording equipment, and were assisted in wearing the sensors, while the supervising staff ensured that the sensors were operating and recording properly. Then, the main recording started and soon the participants were seated for the first main meal, lunch. During the main meals, a variety of servings were available, and participants were free to select any combination and quantity multiple times. Once the meal was over, participants were free and could leave the university premises; no specific script was given to follow. They were instructed however to include at least three distinct eating activities/events (snacks), and at least four physical activities (including walking, running, playing outside, performing typical household tasks, etc) in their routine.
The following table presents some statistics about the dataset.
| Participant | Sessions | Events | Chews | Duration (min) |
| 11 | 1 | 4 | 797 | 154 |
| 31 | 2 | 8 | 2243 | 320 |
| 41 | 2 | 6 | 1171 | 287 |
| 42 | 1 | 6 | 904 | 164 |
| 43 | 1 | 3 | 427 | 68 |
| 51 | 2 | 7 | 1192 | 296 |
| 52 | 4 | 10 | 2269 | 398 |
| 53 | 2 | 7 | 1512 | 297 |
| 61 | 2 | 5 | 1202 | 316 |
| 62 | 1 | 2 | 807 | 104 |
| 63 | 1 | 4 | 670 | 162 |
| 65 | 2 | 5 | 522 | 210 |
| 71 | 4 | 16 | 2274 | 637 |
| 72 | 1 | 3 | 822 | 162 |
Extracted features
Regarding the recorded data, we provide the raw PPG signal, sampled at 64/3 Hz, along with two control signals sampled at the same frequency. These control signals consist of an index corresponding to the level of the current going through the LED, and the amplification gain of the A/D converter. The PPG signal values are stored as 15-bit unsigned integers. A set of ten features are also available corresponding to the non-normalized and normalized (histogram) time varying spectrum (TVS) in five log-bands (0:0-1:0, 1:0-1:8, 1:8-3:3, 3:3-5:9 and 5:9-10:7 Hz).
Audio was originally recorded at 48 kHz; it was subsequently downsampled at 2 kHz and 15 features were extracted [2], including the fractal dimension (FD) [3], condition number (CN) of the 6×6 auto-correlation matrix, four 3rd and 4th order statistics and TVS in nine log bands (0:0-4:0, 4:0-7:4, 7:4-15:8, 15:8-31:6, 31:6-63:0, 63:0-125:9, 125:9-251:2, 251:2-501:2, and 501:2-1000 Hz). The recorded raw audio is not publicly available due to privacy restrictions. As a reference point regarding recording quality and conditions, two staff members tested the equipment a day before the first recording trial; their recordings are also available (both original recordings at 48 kHz and downsampled at 2 kHz in FLAC format, as well as the features). Finally, 3D accelerometer signals are also sampled at 64 3 Hz and are stored as floating point numbers, measured in gs.
The SPLENDID chewing detection challenge
- PPG features: the first challenge is to identify and extract features from the PPG signal that can be used to effectively discriminate chewing from non-chewing. Currently, only spectral features are used that identify the “rhythmic” pattern of chews within a chewing bout.
- PPG-based detection: this challenge involves designing effective chewing detectors based on the features of the first challenge, or the ones provided with the dataset.
- Audio-based detection: further increasing the effectiveness of audio-based classifiers.
- Fusion-based detection: combining all available signals and features to improve detection.
References
[1] V. Papapanagiotou, C. Diou, L. Zhou, J. van den Boer, M. Mars and A. Delopoulos, “The SPLENDID chewing detection challenge,” 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, South Korea, 2017, pp. 817-820.
doi: 10.1109/EMBC.2017.8036949
URL: http://ieeexplore.ieee.org/document/8036949/
[2] V. Papapanagiotou, C. Diou, L. Zhou, J. van den Boer, M. Mars and A. Delopoulos, “A Novel Chewing Detection System Based on PPG, Audio, and Accelerometry,” in IEEE Journal of Biomedical and Health Informatics, vol. 21, no. 3, pp. 607-618, May 2017.
doi: 10.1109/JBHI.2016.2625271
URL: http://ieeexplore.ieee.org/document/7736096/
[3] V. Papapanagiotou, C. Diou, L. Zhou, J. van den Boer, M. Mars and A. Delopoulos, “Fractal Nature of Chewing Sounds,” in New
Trends in Image Analysis and Processing – ICIAP 2015 Workshops, ser. Lecture Notes in Computer Science. Springer International Publishing, 2015, vol. 9281, pp. 401–408. [Online].
URL: http://dx.doi.org/10.1007/978-3-319-23222-5_49